PytorchでCNNを使って画像データから回帰分析をしてみた
作成: 2021年02月24日
更新: 2021年03月29日
概要
画像データを用いた分類モデルの作成例は多くあるが回帰モデルの作成例はあまり多くない.なので画像データから書くのにかかった時間を推定する回帰モデル作成をしてみた.
ソースコードは以下
リポジトリ→bana118/image-and-video-recognition-exercises
学習,検証のソースコード→cnn_reg.py
各モデルでの学習,検証→cnn_reg_search.py
データセット
Canvasに文字を書いてpngとして保存でき,その時間をcsvとして記録してくれる簡単なWebアプリを作りました.
これを使って「書」という文字を40枚,「道」という文字を40枚書いて文字の画像と書くのにかかった時間のペアのデータセットを作成しました.
またtransforms.RandomRotationを用いてランダム回転のデータ拡張を行い文字データをそれぞれ200枚分ずつに拡張しました.
データセットのうち8割を学習用2割を検証用に使用した.
きれいに書いた例(書くのに5430msかかった)

早く書いた例(書くのに2680msかかった)

モデル
モデルはPytorchに用意されてあるプリセットを用いた(torchvision.models — PyTorch 1.7.1 documentation)
クラス数が1000であるImageNetのClassification用のモデルが用意されてあるので最後の層の出力層を1000から1に変更することで回帰モデルとして使えるようにした.
以下はResnet152の出力層を1に変更する例.
# Resnet152の場合
import torch
import torchvision.models as models
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
model = models.resnet152().to(device)
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 1).to(device)プリセットにはVGGやResnetなど有名なものがそろっているのでほとんどすべてで学習と検証を繰り返し,MAEが最小となるモデルを探した.
結果
MAEが最小となったのはGoogleによって開発されたInception V3というモデルでMAEは最小で224msとなった.
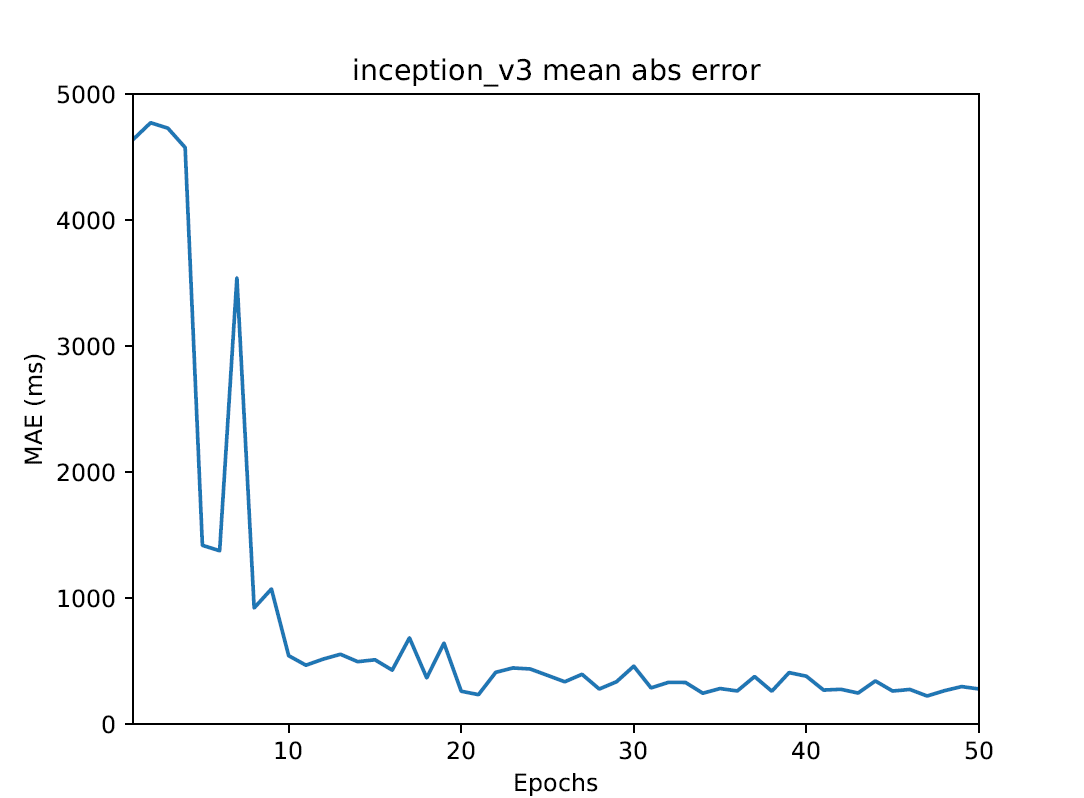
書くのにかかった時間を誤差0.2秒で推定できたので実用性はともかくなかなかうまく推定できたと思う.
またResnet152の誤差も450msだったり他のモデルもまあまあうまく推定できてる.

他の文字の書く時間の推定
線の粗さと書く時間の普遍的な関係がとらえられているか試すためInception V3を用いて「書」という文字で学習した後「道」という文字で検証してみたりその逆をしてみたりしてみた.その結果MAEは以下の表のようになった.
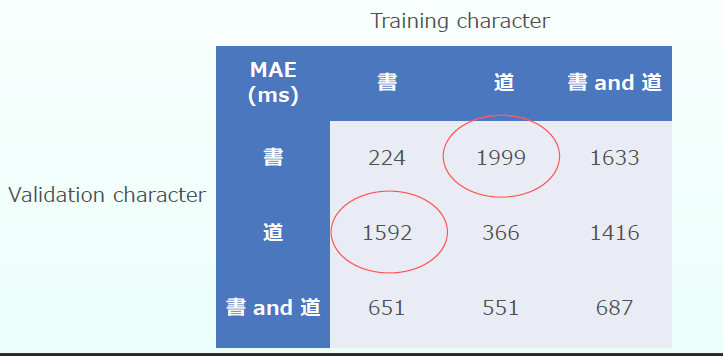
赤丸で囲っている通り学習時と異なる文字の書く時間の推定は誤差が1.5秒を超えていて全然推定できていない.やはり文字の種類を変えるとそう簡単には推定できないようだった.